[Paper Review] The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only (2023)
저자 : The Falcon LLM team

Abstract
- 핵심
- 적절히 필터링 & 중복제거한 웹 데이터는 좋은 모델을 만들 수 있게 한다 !
we show that properly filtered and deduplicated web data alone can lead to powerful models
- 적절히 필터링 & 중복제거한 웹 데이터는 좋은 모델을 만들 수 있게 한다 !
- 배경
- as larger models requiring pretraining on trillions of tokens are considered, it is unclear how scalable is curation and whether we will run out of unique high-quality data soon
1. Introduction
Contributions.
- We introduce REFINEDWEB, a high-quality five trillion tokens web-only English pretraining dataset
- We demonstrate that web data alone can result in models outperforming both public and private curated corpora, as captured by zero-shot benchmarks, challenging current views about data quality
- We publicly release a 600B tokens extract of RefinedWeb, and 1/7B parameters LLMs trained on it, to serve as a new baseline high-quality web dataset for the natural language processing community.
3. Macrodata Refinement and RefinedWeb
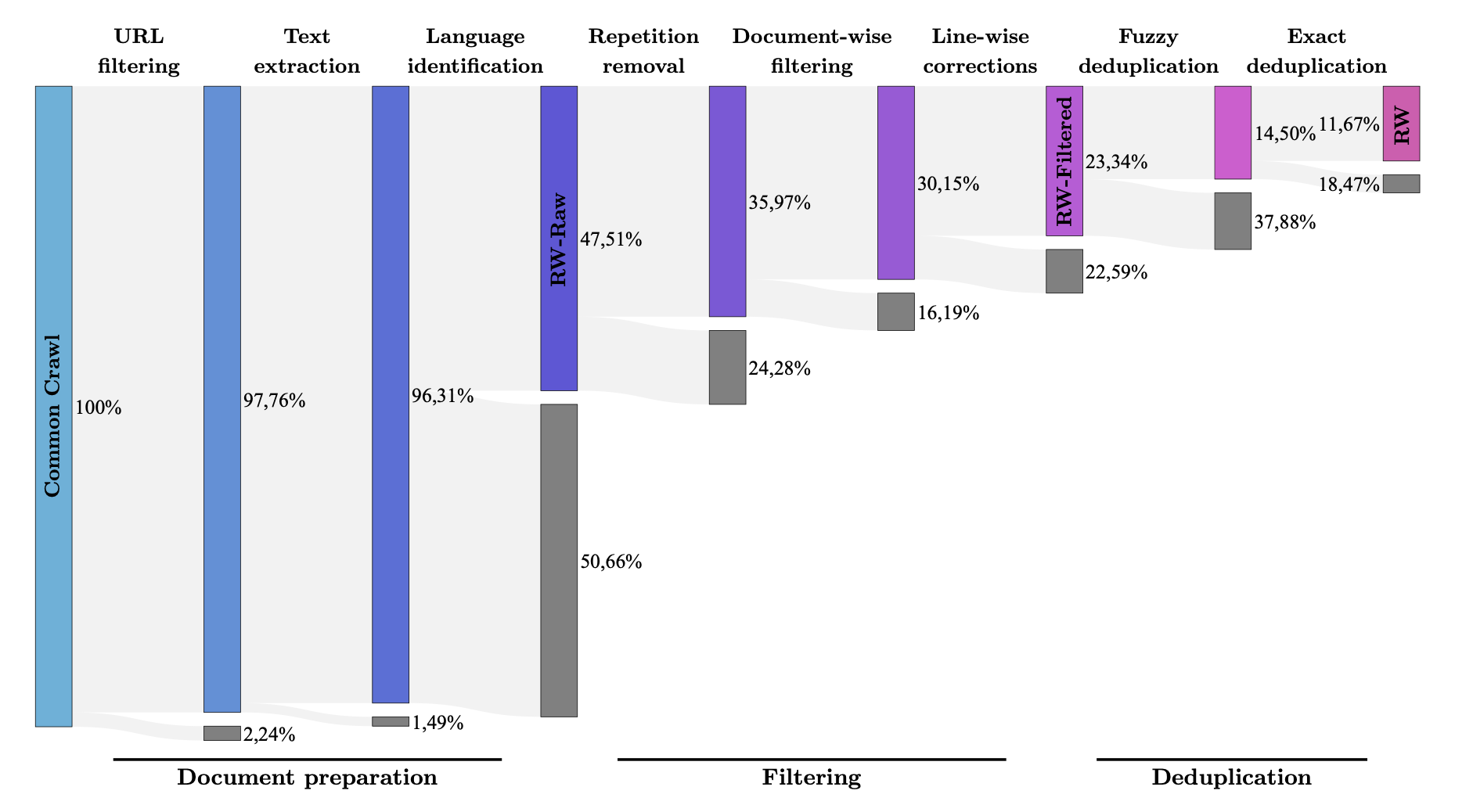
- MDR (MacroData Refinement): 필터링 & 중복제거 파이프라인
- We introduce MDR (MacroData Refinement), a pipeline for filtering and deduplicating web data from CommonCrawl at very large scale
- Using MDR, we produce REFINEDWEB
3.1. Document preparation
Reading data
- 데이터 선정
- CommonCroll 데이터셋 사용
- WARC, WET 파일 중 WARC을 사용함
- WARC (raw HTML response), WET files (preprocessed to only include plain text
- our pipeline starts from raw WARC files, read with the warcio library
- why WARC? : WET files to include undesirable navigation menus, ads
URL Filtering
- we base our filtering of adult documents only on the URL itself, and not on the content of the documents.

- URL blocklist
- we aggregated a list of 4.6M domains, that we explicitly ban.
- We select categories likely to contain adult or malicious content, as well as spam or unstructured text.
- URL scoring
- Common HQ sources blocked
Extracting Text
- From WARC using warcio, trafilatura for text extraction
Language Identification
- 설명
- 58.20% of all documents in the processed CommonCrawl data were identified as English
- we classify processed CommonCrawl data into 176 languages.
- 방법
- We use the fastText language classifier of CCNet (Wenzek et al., 2020) at the document level
- We remove documents for which the top language scores below 0.65
3.2. Filtering: document-wise and line-wise
Repetition Removal
In-document repetition removal
- We could catch this content at the later deduplication stage, but it is cheaper and easier to catch it document-wise early on.
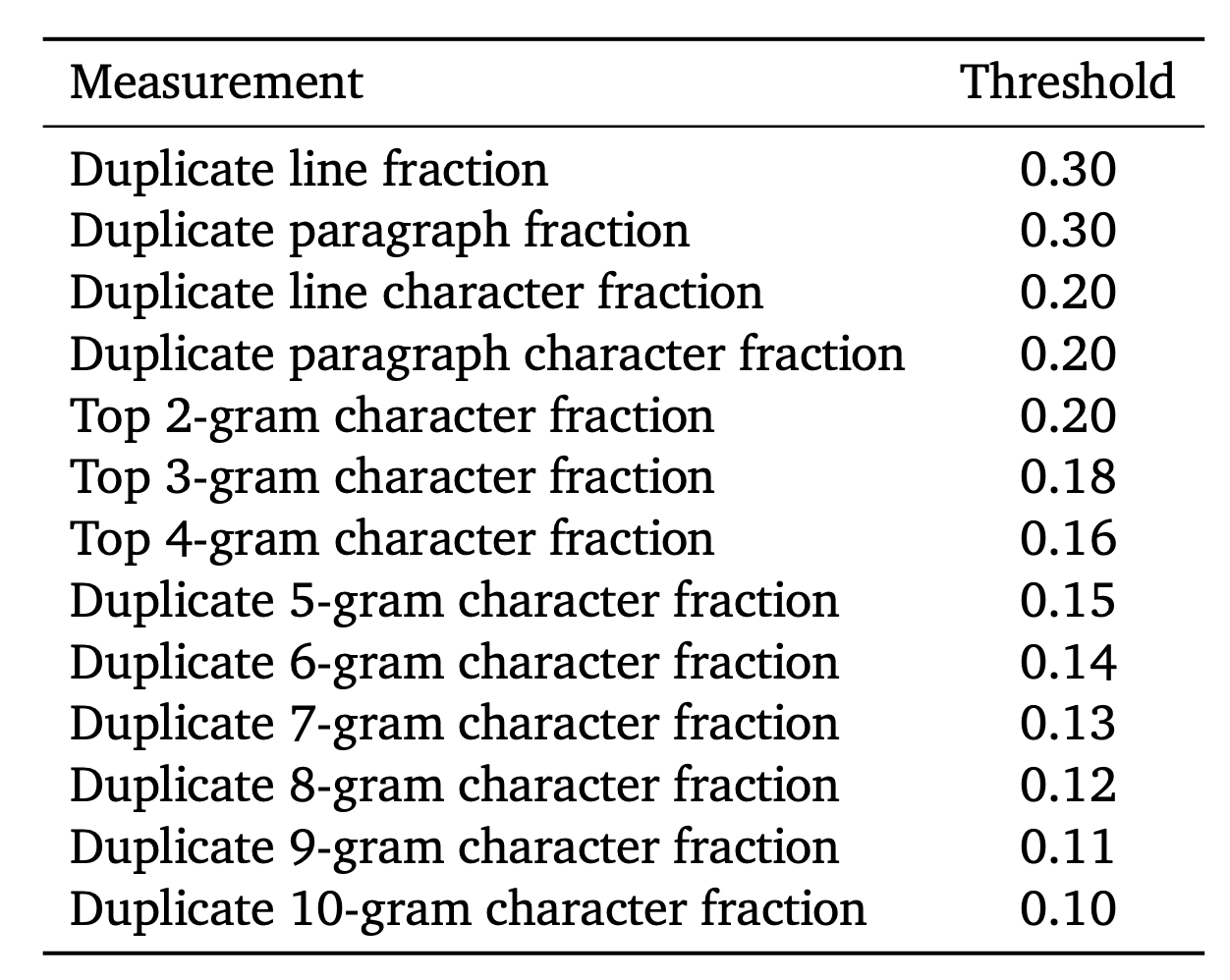
- removing documents with a high proportion of repeated lines, paragraphs, or 𝑛-grams.*
*참조문서 : Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Deepmind
Document-wise Filtering
quality heuristics
- 대상
- machine-generated spam, made predominantly of lists of keywords, boilerplate text, or sequences of special characters
- 방법*
- remove any document that does not contain between 50 and 100,000 words, or whose mean word length is outside the range of 3 to 10 characters
- we remove any document with a symbol-to-word ratio greater than 0.1 for either the hash symbol or the ellipsis
- we remove any document with more than 90% of lines starting with a bullet point, or more than 30% ending with an ellipsis
- We also require that 80% of words in a document contain at least one alphabetic character, and apply a "stop word" filter, to remove documents that do not contain at least two of the following English words: the, be, to, of, and, that, have, with
*참조문서: Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Deepmind 중 quality filtering
Line-wise Filtering
Remove undesirable lines
- If these corrections remove more than 5% of a document, we remove it entirely.
- 대상
- undesirable lines (e.g., call to actions, navigation buttons, social counters, etc)
- 방법
- We analyse documents line-by-line, and discard or edit the lines based on the following rules: (사진 참조)
- Finally, if the words in the flagged lines represent more than 5% of the total document words, the document is discarded.

3.3. Deduplication: fuzzy, exact, and across dumps
Fuzzy deduplication.
- 방법
- We perform MinHash deduplication using 9,000 hashes per document, calculated over 5-grams and divided into 20 buckets of 450 hashes.
- 느슨한 세팅을 사용하면, 중복 제거율이 낮아지고, 이는 모델 퍼포먼스를 저하시킨다.
Using less aggressive settings, such as the 10 hashes of The Pile (Gao et al., 2020),
resulted in lower deduplication rates and worsened model performance.
Exact deduplication.
Exact substring operates at the sequence-level instead of the document-level, finding matches between strings that are exact token-by-token matches by using a suffix array
- 방법
- We remove any match of more than 50 consecutive tokens, using the implementation of Lee et al.
'Deduplicating Training Data Makes Language Models Better' 논문 중 4.1 Exact Substring Duplication*
code: https://github.com/google-research/deduplicate-text-datasets
- We note that exact substring alters documents, by removing specific spans
- document를 통으로 drop 하거나, loss-masking을 하는 방법을 시도해봤으나 두드러지는 효과가 없었다.
이 논문의 Data Pipeline 부분을 세밀하게 살펴 보았습니다.
- 논문 본문에는 Pipeline 각각 기능에 대한 소개, Appendix에는 각 기능을 실제 세팅에 대한 자세한 설명이 나와있습니다. Appendix를 꼭 한 번 읽어보시기를 추천합니다.
- Deepmind의 Scaling Language Models: Methods, Analysis & Insights from Training Gopher 논문도 많이 참고한 것으로 보입니다.
- 데이터셋도 허깅페이스에 올라와있네요.
- Paper : https://arxiv.org/pdf/2306.01116
- HuggingFace: https://huggingface.co/datasets/tiiuae/falcon-refinedweb
tiiuae/falcon-refinedweb · Datasets at Hugging Face
The fashionable Tokyo thoroughfare of Omotesando invariably bustles with hordes of young people, but turn away from its rows of Zelkova trees and head down one of its back streets, and peace and quiet prevail. This is where it all started for hairdresser H
huggingface.co